这是很早以前百度公布的网站作弊相关的内容,这个内容现在已经不知道放在哪个页面去了,但是核桃从石头的博客上看到了这个内容,存过来作为一个备份吧.
1. 作弊网站定义
对搜索引擎作弊,是指为了提高在搜索引擎中展现机会和排名的目的,欺骗搜索引擎的行为。
以下行为都可能被认为是作弊:
· 在网页源代码中任何位置,故意加入与网页内容不相关的关键词;
· 在网页源代码中任何位置,故意大量重复某些关键词
这是很早以前百度公布的网站作弊相关的内容,这个内容现在已经不知道放在哪个页面去了,但是核桃从石头的博客上看到了这个内容,存过来作为一个备份吧.
1. 作弊网站定义
对搜索引擎作弊,是指为了提高在搜索引擎中展现机会和排名的目的,欺骗搜索引擎的行为。
以下行为都可能被认为是作弊:
· 在网页源代码中任何位置,故意加入与网页内容不相关的关键词;
· 在网页源代码中任何位置,故意大量重复某些关键词
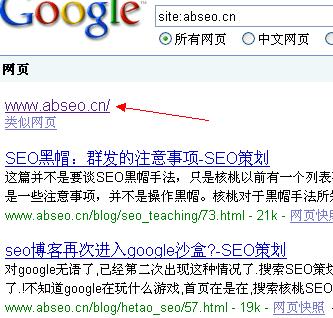
总共收录了两个内页,但是依然看不到快照.而且首页出现了问题.
看上图的红色箭头,为什么会这样呢?引发这个结果的原因不在 Robots.txt ,因为现在根本就没有禁止谷歌蜘蛛,那是为什么?
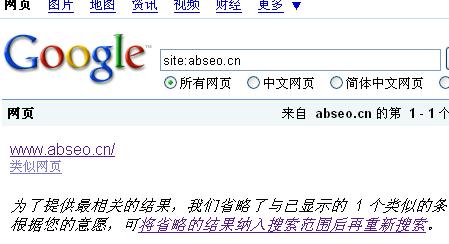
从第一篇核桃SEO博客大门向GOOGLE关闭开始,到非常奇怪的Google蜘蛛的文章发布至今,历时3个月又10天.谷歌终将所有的内容清理完了.
由于我前面设置的时候没有想到谷歌会有一个RSS蜘蛛:Feedfetcher-Google,所以导致最后留下很多XML的文件被收录没有清理。
不过很快的,在我重新设置了这个蜘蛛禁止访问后,不到半个月时间,谷歌就反应过来,并且将这些内容清除掉了。