从第一篇核桃SEO博客大门向GOOGLE关闭开始,到非常奇怪的Google蜘蛛的文章发布至今,历时3个月又10天.谷歌终将所有的内容清理完了.
由于我前面设置的时候没有想到谷歌会有一个RSS蜘蛛:Feedfetcher-Google,所以导致最后留下很多XML的文件被收录没有清理。
不过很快的,在我重新设置了这个蜘蛛禁止访问后,不到半个月时间,谷歌就反应过来,并且将这些内容清除掉了。
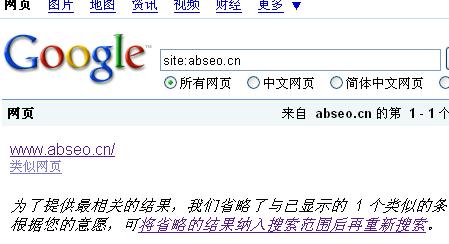
今天的截图就在上面,可以看到SITE的结果只有一个域名,但是后面的提示也是有内容的,看下图:
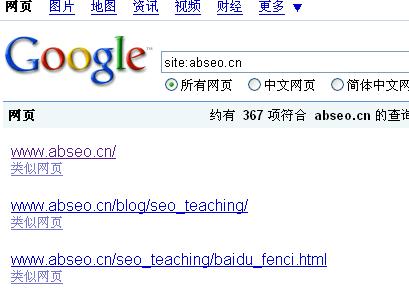
可以发现所有的页面都还存在收录的情况,但这些页面没有快照也没有标题,基本上只是一个存在的痕迹。
核桃觉得可能这是谷歌对待已有内容并且存在的一种形式,因为被我禁止收录了,所以谷歌为了遵守robots协议,不能将这些内容存进他们的收录内容里,由于前面的收录,谷歌又不得不让这些URL存在一段时间.
不过个人认为,谷歌有可能还是存有这些页面的最后时间快照的,只不过为了ROBOTS协议,谷歌不能将这些内容透露给网民,所以无论我们如何进行查找,都不可能在谷歌的收录内容里查到这些信息了。
本站已经在2009.3.8对谷歌开放了robots,因为已经测试完了,所以有必要开放一下,并且为下一次研究谷歌做好准备,让我们再看一下谷歌会用多久才能完全恢复到以前的收录情况吧!
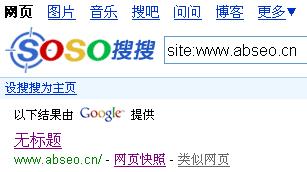
最后提供SOSO的情况给大家看下,不过“网页快照”的内容是跳转到谷歌的,看不到任何与本博客相关的内容。